



Data in the Fast Lane: How NVLink Unleashes Application Performance
OREANDA-NEWS. April 24, 2015. If your day starts by crawling to work through traffic, you’ve wished that the four-lane highway could expand into eight.
Applications experience traffic jams, too. It happens when the few, narrow lanes between the CPU and the GPU — known as the PCI Express (PCIe) bus — can’t keep up with the flow of data.
GPUs can crunch through a lot of data fast. But taking full advantage of this ability requires that massive amounts of data must be constantly fed to the GPU. The PCIe interconnect often can’t keep pace.
To avoid these “traffic jams,” we invented a fast interconnect between the CPU and GPU, and among GPUs. It’s called NVLink.
It’s the world’s first high-speed interconnect technology for GPUs. NVIDIA NVLink creates a data super-highway in next-gen HPC servers. One that lets GPUs and CPUs exchange data among each other five to 12 times faster than with PCIe.
When we unveiled NVLink last year, the industry took notice. IBM’s integrating it into future POWER CPUs. And the U.S. Department of Energy announced that GPUs and NVLink will power its next flagship supercomputers.
NVLink will be available in GPUs based on our forthcoming Pascal architecture. But here’s a sneak peek of how it can improve application performance by speeding up data movement in multi-GPU configurations.
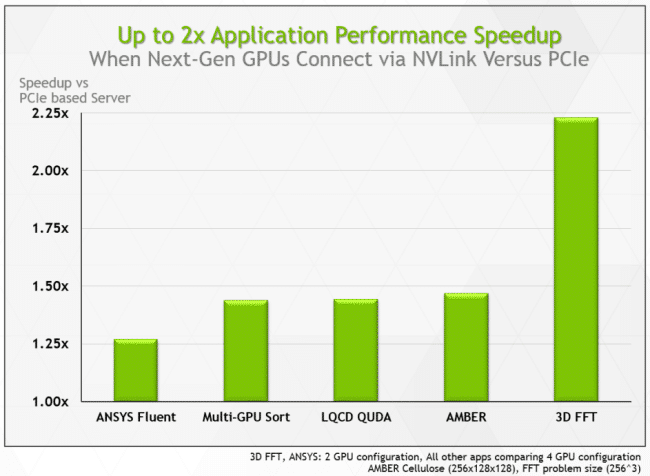
FFT Algorithm Better Than 2x Faster
Fast Fourier Transform (FFT) is an algorithm widely used for seismic processing, signal processing, image processing, and partial differential equations.
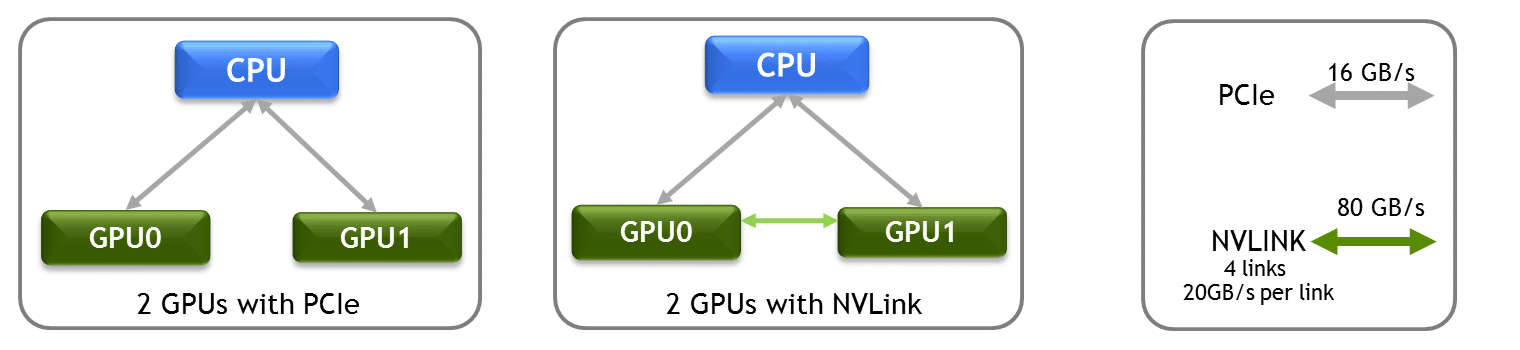
FFT is often run on servers that attach two GPUs to a single CPU socket via a PCIe bus. To distribute the FFT workload, the two GPUs exchange large amounts of data. But the PCIe bus becomes a bottleneck — with GPUs sharing data at only 16 gigabytes per second (GB/s).
Connecting the two GPUs via NVLink allows them to communicate at 80 GB/s. That’s 5x faster.
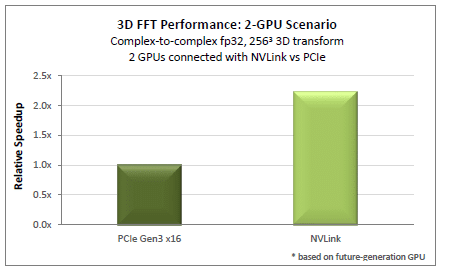
With NVLink, FFT-based workloads can run more than 2x faster than on a PCIe-based system.
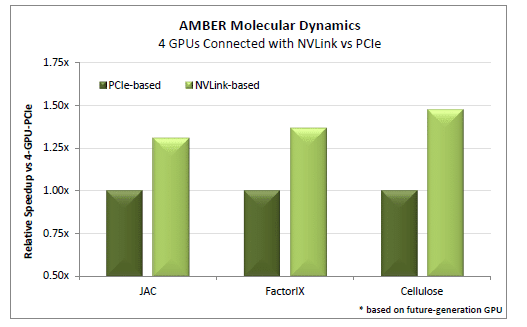
Up to 50% Faster Performance for AMBER
AMBER is a molecular dynamics application used to study the behavior of matter, such as cancer cells, on the atomic level. GPUs let researchers simulate molecular structures on AMBER at a higher level of accuracy, while reducing run times from weeks to days.
Researchers are building denser server configurations to run AMBER and other workloads. Many attach up to four GPUs to a single CPU socket.
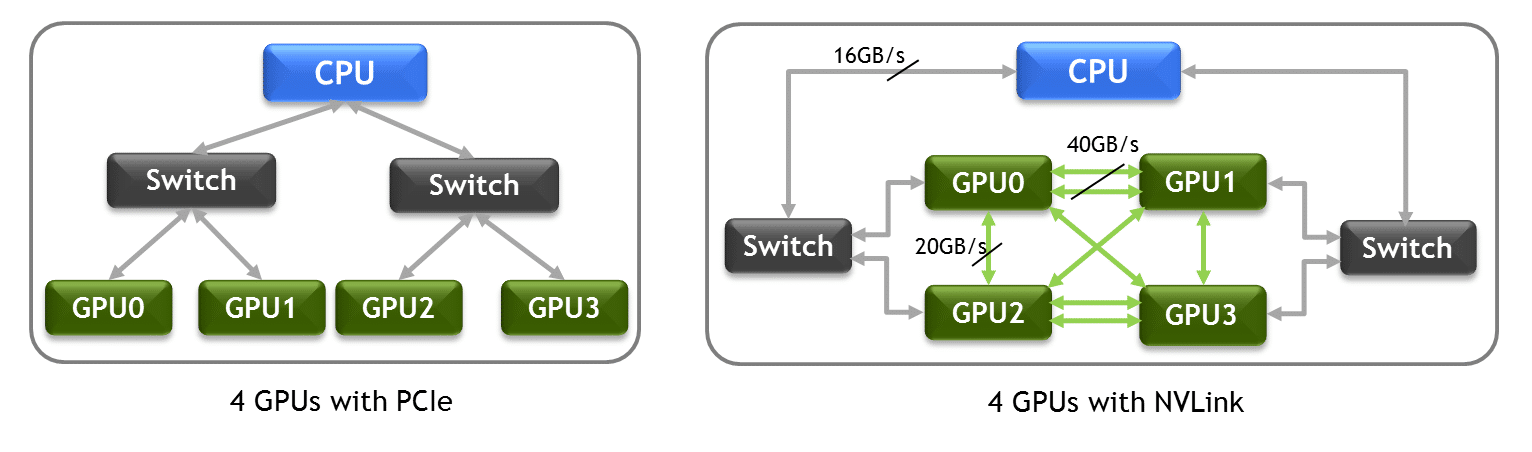
AMBER needs to exchange data continuously when running simulations across GPUs. PCIe chugs along. But with NVLink connecting four GPUs, AMBER can run 30 to 50 percent faster.
Комментарии